例えば、A,B二つの集団の身長の平均値の差について考えます。
二群の平均値の差が0.1cm程度しかなかったとき、その差を膨大なサンプリングによって検出することに果たして意味があるのでしょうか。いやありません。
サンプル数は多すぎても問題なのです。
大切なのは、実験を行う前の段階で、どの程度の平均値の差なら実質的に有意であるかを明らかにした上で、必要最小限のサンプルを行うことです。
以下に、サンプル数とp値のシミュレーションの結果を書きます。
$ vim comman.in
result1 <- c(1:99)
for(i in 1:99)
{
#2群の平均値の差が10cmの場合
dat1 <- rnorm(mean=175.0, n=i+1, sd=5)
dat2 <- rnorm(mean=185.0, n=i+1, sd=5)
result1[i] <- t.test(dat1,dat2,alternative="two.side",mu=0, paired=FALSE,var.equal=FALSE,conf.level=0.95)$p.value
}
result2 <- c(1:99)
for(i in 1:99)
{
#2群の平均値の差が5cmの場合
dat1 <- rnorm(mean=175.0, n=i+1, sd=5)
dat2 <- rnorm(mean=180.0, n=i+1, sd=5)
result2[i] <- t.test(dat1,dat2,alternative="two.side",mu=0, paired=FALSE,var.equal=FALSE,conf.level=0.95)$p.value
}
result3 <- c(1:99)
for(i in 1:99)
{
#2群の平均値の差が1cmの場合
dat1 <- rnorm(mean=175.0, n=i+1, sd=5)
dat2 <- rnorm(mean=176.0, n=i+1, sd=5)
result3[i] <- t.test(dat1,dat2,alternative="two.side",mu=0, paired=FALSE,var.equal=FALSE,conf.level=0.95)$p.value
}
n <- c(2:100)
png("120731_n.png")
par(mfrow=c(1,3))
plot(n,result1)
plot(n,result2)
plot(n,result3)
dev.off()
$ R
> source("command.in")

平均値の差が小さくなると、統計的に有意であると判断されるのに多くのサンプルが必要であることがわかりました。
次に、平均値の差が1cmの時に、さらにサンプル数を多くして検証します。
対照群として、平均値の差がない群の比較を提示しています。
> cntrl-z
$ vim command.in.2
result4 <- c(1:999)
for(i in 1:999)
{
dat1 <- rnorm(mean=175.0, n=i+1, sd=5)
dat2 <- rnorm(mean=176.0, n=i+1, sd=5)
result4[i] <- t.test(dat1,dat2,alternative="two.side",mu=0, paired=FALSE,var.equal=FALSE,conf.level=0.95)$p.value
}
result5 <- c(1:99)
for(i in 1:999)
{
dat1 <- rnorm(mean=175.0, n=i+1, sd=5)
dat2 <- rnorm(mean=175.0, n=i+1, sd=5)
result5[i] <- t.test(dat1,dat2,alternative="two.side",mu=0, paired=FALSE,var.equal=FALSE,conf.level=0.95)$p.value
}
n <- c(2:1000)
png("120731_n_2.png")
par(mfrow=c(1,2))
plot(n,result4)
plot(n,result5)
dev.off()
$ fg
> source("command.in.2")
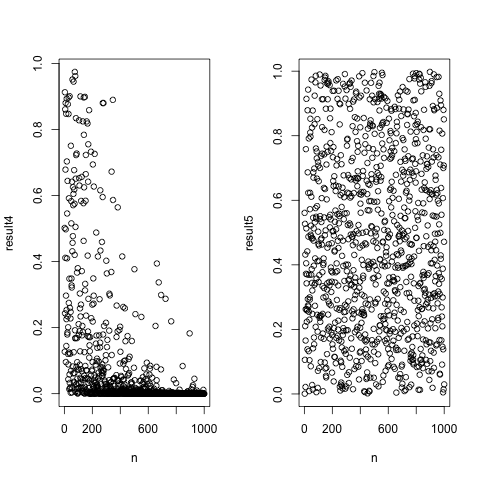
確かに、1000サンプル近く抽出すればそれなりに有意差が出てくるようですが、この作業に何の意味があるのでしょうか(いやない)。
あらかじめ有意であると見なすことのできる差を想定した上でその差を検出するのに必要最低限なサンプルを確保することが王道ではないかと思います。
やたらめったら、サンプルを増やしてp<0.05としたところで、その差が実際のところどの程度の影響を持つのか考える必要があろうかと思います。