LAMP環境で、サッカー選手の背番号、名前、ポジションを管理するアプリケーションを作成しました。
作業工程は
(1)データベースの作成
(2)登録用フォームの作成
(3)サーバーサイドでデータベースにアクセスするPHPスクリプトの作成
(4)データベースの情報を取得して表示するPHPスクリプトの作成
の4つです。
ドキュメント以下のフィアル構成は下のようになります。
DocumentRoot
└── web
├── form.html
├── test.php
└── uke.php
##### (1) データベース(player)の作成####
#playerデータベースを作成し、useする
mysql> create database player;
Query OK, 1 row affected (0.00 sec)
mysql> use player;
Database changed
#playerデータベースの中にplayerテーブルを作成
mysql> CREATE TABLE player (number smallint, name text, position text, date timestamp) engine=MyISAM;
Query OK, 0 rows affected (0.31 sec)
#データを入力
mysql> insert into player (number, name, position, date) values ( 1 , '川口能活', 'GK', now());
Query OK, 1 row affected (0.00 sec)
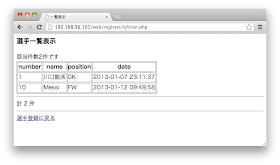
mysql> select number, name, position, date from player;
+--------+--------------+----------+---------------------+
| number | name | position | date |
+--------+--------------+----------+---------------------+
| 1 | 川口能活 | GK | 2013-01-07 23:11:37 |
+--------+--------------+----------+---------------------+
1 row in set (0.00 sec)
#####ここまで#####
#####(2)フォームの作成(/var/www/web/register.html)####
<html lang="ja">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>選手名鑑</title>
</head>
<body>
<form method="POST" action="register.php">
<p>選手名鑑入力フォーム</p>
<p>背番号 <input type="text" name="number"></p>
<p>名前 <input type="text" name="name"></p>
<p>ポジション <input type="text" name="position"></p>
<input type="submit" value="登録">
</form>
<a href=./ichiran.php>登録選手一覧を見る</a>
</body>
</html>
####ここまで#####
####(3)フォームの入力情報をもとにデータベースにアクセスするスクリプト(register.php)###
<?php
//---------データの受け取り
$num = $_POST['number'];
$nam = $_POST['name'];
$pos = $_POST['position'];
//---------データベースのユーザー情報
$DBSERVER ="localhost";
$DBUSER="kappa";
$DBPASS ="kappa";
$DBNAME ="player";
///------------MySQLに接続
$con = mysql_connect($DBSERVER, $DBUSER, $DBPASS);
///------------エラー処理1
if(!$con){
echo "データベース接続開始エラー<br>\n";
mysql_close($con);
exit;
}
///------------playerデータベースに接続
$selectdb = mysql_select_db($DBNAME);
///------------playerテーブルに入力
$query = "insert into player (number, name, position, date) values ('$num','$name','$pos',now())";
$result = mysql_query($query);
///------------エラー処理2
if(!$result){
echo "データベースエラー<br>\n";
mysql_close($con);
exit;
}
?>
<html lang="ja">
<head>
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<title>選手情報登録完了</title>
</head>
<body>
<p>登録が完了しました(〃 ̄∇ ̄)ノ</p>
<a href="./ichiran.php">選手情報の一覧を見る</a>
</body>
</html>
####ここまで####
#### (4)データベースの内容を表示するスクリプト#####
<?php
echo "<HTML lang=ja>\n";
echo "<HEAD>\n";
echo "<META HTTP-EQUIV=Content-Type CONTENT=text/html; CHARSET=UTF-8>\n";
echo "<TITLE>一覧表示</TITLE>\n";
echo "</HEAD>\n";
echo "<BODY>";
echo "<h3><p>選手一覧表示</h3></p>";
///-----------データベース情報
$DBSERVER ="localhost";
$DBUSER="kappa";
$DBPASS ="kappa";
$DBNAME ="player";
///------------MySQLに接続
$con = mysql_connect($DBSERVER, $DBUSER, $DBPASS);
///------------エラー処理1
if(!$con){
echo "データベース接続開始エラー<br>\n";
mysql_close($con);
exit;
}
///------------データベースを選択
$selectdb = mysql_select_db($DBNAME);
///------------クエリを送る
$query = "select * from player; ";
///------------結果の取得
$result = mysql_query($query);
///------------エラー処理1
if(!$result){
echo "データベースエラー<br>\n";
mysql_close($con);
exit;
}
///------------行数を取得
$num_row = mysql_numrows($result);
$num_field = mysql_num_fields($result);
echo "該当件数".$num_row."件です<br>\n";
echo "<table border=1>\n";
echo "<tr>\n";
///+++++++++ 列名 ++++++++++
for($i =0; $i < $num_field; $i++){
echo "<th>".mysql_field_name($result, $i)."</th>";
}
///+++++++++ レコード表示 ++++++++++
for($j =0 ; $j < $num_row; ++$j){
$row = mysql_fetch_array($result);
echo "<tr>";
for($k=0; $k < $num_field; ++$k){
echo "<td>".$row[$k]."</td>";
}
echo "</tr>\n";
}
echo "</table>";
echo "<hr>計 $num_row 件<hr>\n";
///+++++++++ mysqlを切断 ++++++++++
mysql_close($con);
echo "<a href=./register.php>選手登録に戻る</a>";
echo "</BODY></HTML>";
?>
####ここまで#####
【参考文献】
清水正人 『6時間でできるLAMPサーバー構築ガイド』ソシム 2007 98 - 109 ,132 - 143pp