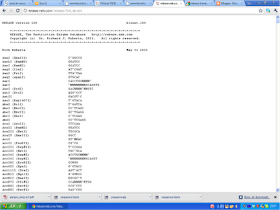
#freeコマンドでメモリの使用状況を調べる。
$ free
total used free shared buffers cached
Mem: 499364 485288 14076 0 23072 169652
-/+ buffers/cache: 292564 206800
Swap: 1533948 14656 1519292
メモリの上に展開されたプログラムの中で、使用頻度の低いものをSwap領域に移動させているため、Swapが14MBだけ移動されていることが分かる。Linux OSは使用を続ければ続けただけ、メモリがキャッシュに割り当てられる。そのため、"Mem:"の行ではfreeが1.4MBしか残っていない。
Linuxにおいて真にメモリの空き容量を知るには、バッファーとキャッシュを考慮に入れた値を見る必要がある。今回は、292MBの空き領域があるということである。
htmlファイルの基本構造_javascriptの手始め_2
1 <html>
2
3 <head>
4 <title>
5 ホームページのタイトルをいれるねん。
6 </title>
7 </head>
8
9
10
11 <body text="green" bgcolor="yellow">
12
13 <script type="text/javascript">
14 <!--
15 window.alert("こんなのもいかが?");
16 -->
17 </script>
18
19 ここに本文を書くねん。
20 </body>
21
22
23 <html>


2
3 <head>
4 <title>
5 ホームページのタイトルをいれるねん。
6 </title>
7 </head>
8
9
10
11 <body text="green" bgcolor="yellow">
12
13 <script type="text/javascript">
14 <!--
15 window.alert("こんなのもいかが?");
16 -->
17 </script>
18
19 ここに本文を書くねん。
20 </body>
21
22
23 <html>


htmlファイルの基本構造_javascriptの手始め
1 <html>
2
3 <head>
4 <title>
5 ホームページのタイトルをいれるねん。
6 </title>
7 </head>
8
9
10
11 <body text="green" bgcolor="yellow">
12
13 <script type="text/javascript">
14 <!--
15 document.write("ここにも文字が書けるねん。");
16 document.write("<br>");
17 -->
18 </script>
19
20 ここに本文を書くねん。
21 </body>

2
3 <head>
4 <title>
5 ホームページのタイトルをいれるねん。
6 </title>
7 </head>
8
9
10
11 <body text="green" bgcolor="yellow">
12
13 <script type="text/javascript">
14 <!--
15 document.write("ここにも文字が書けるねん。");
16 document.write("<br>");
17 -->
18 </script>
19
20 ここに本文を書くねん。
21 </body>

htmlファイルの基本構造_2
1 <html>
2
3 <head>
4 <title>
5 ホームページのタイトルをいれるねん。
6 </title>
7 </head>
8
9
10 <body text="green" bgcolor="yellow">
11 ここに本文を書いくねん。
12 </body>
13
14 <html>

2
3 <head>
4 <title>
5 ホームページのタイトルをいれるねん。
6 </title>
7 </head>
8
9
10 <body text="green" bgcolor="yellow">
11 ここに本文を書いくねん。
12 </body>
13
14 <html>

htmlファイルの基本構造
1 <html>
2
3 <head>
4 <title>
5 ホームページのタイトルをいれるねん。
6 </title>
7 </head>
8
9 <body>
10 ここに本文を書いくねん。
11 </body>
12
13 <html>
#実行してみよう。
$ firefox test.html

2
3 <head>
4 <title>
5 ホームページのタイトルをいれるねん。
6 </title>
7 </head>
8
9 <body>
10 ここに本文を書いくねん。
11 </body>
12
13 <html>
#実行してみよう。
$ firefox test.html

コマンドラインからCPUとメモリの性能を見る
コマンドラインからCPUとメモリの性能を見るには、/proc/cpuinfoと、 /proc/meminfoのファイルを閲覧してやればいいです(^^)
CPUの性能チェック
$ cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 23
model name : Intel(R) Core(TM)2 Quad CPU Q9400 @ 2.66GHz
stepping : 10
cpu MHz : 2660.030
cache size : 3072 KB
fdiv_bug : no
hlt_bug : no
f00f_bug : no
coma_bug : no
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss nx constant_tsc up arch_perfmon pebs bts xtopology tsc_reliable aperfmperf pni ssse3 sse4_1 hypervisor
bogomips : 5320.06
clflush size : 64
cache_alignment : 64
address sizes : 40 bits physical, 48 bits virtual
#メモリの容量を確認
$ cat /etc/meminfo
~$ cat /proc/meminfo
MemTotal: 509240 kB
MemFree: 50796 kB
Buffers: 36988 kB
Cached: 160704 kB
SwapCached: 1888 kB
Active: 191044 kB
Inactive: 226124 kB
Active(anon): 96632 kB
Inactive(anon): 131360 kB
Active(file): 94412 kB
Inactive(file): 94764 kB
Unevictable: 16 kB
Mlocked: 16 kB
HighTotal: 0 kB
HighFree: 0 kB
LowTotal: 509240 kB
LowFree: 50796 kB
SwapTotal: 1489912 kB
SwapFree: 1483168 kB
Dirty: 56 kB
Writeback: 0 kB
AnonPages: 218052 kB
Mapped: 57052 kB
Shmem: 8516 kB
Slab: 27664 kB
SReclaimable: 19848 kB
SUnreclaim: 7816 kB
KernelStack: 2008 kB
PageTables: 5316 kB
NFS_Unstable: 0 kB
Bounce: 0 kB
WritebackTmp: 0 kB
CommitLimit: 1744532 kB
Committed_AS: 831560 kB
VmallocTotal: 507896 kB
VmallocUsed: 6544 kB
VmallocChunk: 496448 kB
HardwareCorrupted: 0 kB
HugePages_Total: 0
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 4096 kB
DirectMap4k: 16384 kB
DirectMap4M: 507904 kB
コマンドラインからDVD-Rにisoイメージを焼く
cdrecordというアプリケーションを使います。
#APTパッケージマネージャーを用いたcdrecordのインストール
$ sudo apt-get install cdrecord
#ubuntu64bitのisoイメージファイルの置いてあるディレクトリに移動
$ cd /home/kappa/Downloads
#cdrecordが認識しているハードウェアを調べる
$ cdrecord -scanbus
scsibus2:
2,0,0 200) 'MATSHITA' 'DVD-RAM UJ-833S ' '1.51' Removable CD-ROM
2,1,0 201) *
2,2,0 202) *
2,3,0 203) *
2,4,0 204) *
2,5,0 205) *
2,6,0 206) *
2,7,0 207) *
#isoイメージをDVD-Rに焼く
$ cdrecord dev=2,0,0 ubuntu-11.04-<F12>desktop-amd64.iso
#APTパッケージマネージャーを用いたcdrecordのインストール
$ sudo apt-get install cdrecord
#ubuntu64bitのisoイメージファイルの置いてあるディレクトリに移動
$ cd /home/kappa/Downloads
#cdrecordが認識しているハードウェアを調べる
$ cdrecord -scanbus
scsibus2:
2,0,0 200) 'MATSHITA' 'DVD-RAM UJ-833S ' '1.51' Removable CD-ROM
2,1,0 201) *
2,2,0 202) *
2,3,0 203) *
2,4,0 204) *
2,5,0 205) *
2,6,0 206) *
2,7,0 207) *
#isoイメージをDVD-Rに焼く
$ cdrecord dev=2,0,0 ubuntu-11.04-<F12>desktop-amd64.iso
lubuntuでのスクリーンショット
軽量化を求めてlubuntuに移ってきたわけだが、lubuntuは軽量化を推し進めている関係でいくつかの機能がデフォルトでは落とされてしまっている。
そのひとつがスクリーンショットである。
synaptic package マネージャーから”screen shot" と検索して、検索結果の下の方にある
xfce4-screenshooter をインストールすればOKです!
端末からなら、
$ sudo apt-get install xfce4-screenshooter
でインストール可能です(^^)
そのひとつがスクリーンショットである。
synaptic package マネージャーから”screen shot" と検索して、検索結果の下の方にある
xfce4-screenshooter をインストールすればOKです!
端末からなら、
$ sudo apt-get install xfce4-screenshooter
でインストール可能です(^^)
htmlファイルの編集ソフト : KompoZer
vimのようなシンプルなテキストエディターだけでhtmlを書いていると時間がかかってしょうがないので、KompoZerというhtmlファイル編集のお助けソフトを使うことがあります。
#KompoZer のインストール
$ sudo apt-get install kompozer
#kompozerの起動
$ kompozer ファイル名.html &
これで編集できます♪♪
かなり楽ですよ!!
#KompoZer のインストール
$ sudo apt-get install kompozer
#kompozerの起動
$ kompozer ファイル名.html &
これで編集できます♪♪
かなり楽ですよ!!
htmlファイルをgftpを使ってサーバーへアップロード♪
Windowsでホームページ作るときによく使うffftp。
#####################################################
Wikipediaより引用
FFFTPは、1997年に曽田純(Sota)が作成、発表した、代表的なFTPクライアントソフトウェア。開発は現在も続けられている。漢字などのマルチバイト文字を名前に含むファイルを扱えるのが特徴。
#####################################################
ubuntuでは、このffftpは使えませんが、その代わりにgFTPというFTPクライアントソフトウェアが存在します。
http://gftp.seul.org/
#インストールは
$ sudo apt-get install gftp
#アプリケーションの起動は、
$ gftp &
#ためしにごく簡単なhtmlファイルを作成します。
$ vim test.html
1 <html>
2 <head>
3 <title>
4 Hello!!
5 </title>
6 </head>
7 <body>
8 This is my first home page.
9 </body>
10 </html>
#内容をウェブブラウザ(今回はfirefox)で確認するには
$ firefox test.html
#gftp起動
$ gftp &
FC2で作成したホスト名(ユーザー名.web.fc2.com)と、ユーザー名とパスワード(FC2全体のパスワードではなく、ホームページを作成した時に作成したパスワードであることに注意)を入力してあげればOKです。ただし、一番右の項目はFTPを選択します。
ちなみに、私のHPのURLは
http://kappabucha.web.fc2.com/
です(^^)
お時間がありましたら遊びにきてください♪
#####################################################
Wikipediaより引用
FFFTPは、1997年に曽田純(Sota)が作成、発表した、代表的なFTPクライアントソフトウェア。開発は現在も続けられている。漢字などのマルチバイト文字を名前に含むファイルを扱えるのが特徴。
#####################################################
ubuntuでは、このffftpは使えませんが、その代わりにgFTPというFTPクライアントソフトウェアが存在します。
http://gftp.seul.org/
#インストールは
$ sudo apt-get install gftp
#アプリケーションの起動は、
$ gftp &
#ためしにごく簡単なhtmlファイルを作成します。
$ vim test.html
1 <html>
2 <head>
3 <title>
4 Hello!!
5 </title>
6 </head>
7 <body>
8 This is my first home page.
9 </body>
10 </html>
#内容をウェブブラウザ(今回はfirefox)で確認するには
$ firefox test.html
#gftp起動
$ gftp &
FC2で作成したホスト名(ユーザー名.web.fc2.com)と、ユーザー名とパスワード(FC2全体のパスワードではなく、ホームページを作成した時に作成したパスワードであることに注意)を入力してあげればOKです。ただし、一番右の項目はFTPを選択します。
ちなみに、私のHPのURLは
http://kappabucha.web.fc2.com/
です(^^)
お時間がありましたら遊びにきてください♪
EMBOSSを使って、塩基配列を操作。プライマーの設計。
homo sapiens のVEGFA(vascular endothelial growth factor A isoform a)をネタにEMBOSSを使い倒してみる。
#Refseqの配列のuniform sequence address, 名前、アクッセンション番号、核酸配列orアミノ酸配列、配列の長さ、gcの割合、配列の説明を取得
$ infoseq
Display basic information about sequences
Input (gapped) sequence(s): refseq:NM_001025366
USA Database Name Accession Type Length %GC Organism Description
refseq-id:NM_001025366 refseq NM_001025366 NM_001025366 N 3677 51.26 Homo sapiens (human) Homo sapiens vascular endothelial growth factor A (VEGFA), transcript variant 1, mRNA.
#一行でテキストファイルに出力してしまなら
$ infoseq refseq:NM_001025366 -outfile=NM_001025366_infoseq.txt
Reads and writes (returns) sequences
Input (gapped) sequence(s): refseq:NM_001025366
output sequence(s) [nm_001025366.fasta]: NM_001025366.nt
#seqretコマンドを使って塩基配列を取り出す。
Reads and writes (returns) sequences
Input (gapped) sequence(s): refseq:NM_001025366
output sequence(s) [nm_001025366.fasta]: NM_001025366.nt
#一行で書くなら
$seqret refseq:NM_001025366 -outseq NM_001025366
#NM_001025366を毎回入力するのがめんどくさい場合は、テキストファイルの中に
#refseq:NM_001025366と書いたものを用意して、@+ファイル名でseqretの引数に加えてやればよい。この方法だと、複数の配列をテキストファイルの中に書いておけば、一度に複数の配列をダウンロードしてくることができる。
$ seqret @NM_001025366.txt -outseq=NM_001025366
#配列以外の情報もすべてゲットしたいときは、entretコマンドがおすすめ。
$ entret @NM_001025366.txt -outfile=NM_001025366.entret
#配列のアノテーションが書かれているfeatureの部分を可視化するには,showfeatコマンド
$ showfeat @NM_001025366.txt -outfile=NM_001025366.entret
#Refseqの配列のuniform sequence address, 名前、アクッセンション番号、核酸配列orアミノ酸配列、配列の長さ、gcの割合、配列の説明を取得
$ infoseq
Display basic information about sequences
Input (gapped) sequence(s): refseq:NM_001025366
USA Database Name Accession Type Length %GC Organism Description
refseq-id:NM_001025366 refseq NM_001025366 NM_001025366 N 3677 51.26 Homo sapiens (human) Homo sapiens vascular endothelial growth factor A (VEGFA), transcript variant 1, mRNA.
#一行でテキストファイルに出力してしまなら
$ infoseq refseq:NM_001025366 -outfile=NM_001025366_infoseq.txt
Reads and writes (returns) sequences
Input (gapped) sequence(s): refseq:NM_001025366
output sequence(s) [nm_001025366.fasta]: NM_001025366.nt
#seqretコマンドを使って塩基配列を取り出す。
Reads and writes (returns) sequences
Input (gapped) sequence(s): refseq:NM_001025366
output sequence(s) [nm_001025366.fasta]: NM_001025366.nt
#一行で書くなら
$seqret refseq:NM_001025366 -outseq NM_001025366
#NM_001025366を毎回入力するのがめんどくさい場合は、テキストファイルの中に
#refseq:NM_001025366と書いたものを用意して、@+ファイル名でseqretの引数に加えてやればよい。この方法だと、複数の配列をテキストファイルの中に書いておけば、一度に複数の配列をダウンロードしてくることができる。
$ seqret @NM_001025366.txt -outseq=NM_001025366
#配列以外の情報もすべてゲットしたいときは、entretコマンドがおすすめ。
$ entret @NM_001025366.txt -outfile=NM_001025366.entret
#配列のアノテーションが書かれているfeatureの部分を可視化するには,showfeatコマンド
$ showfeat @NM_001025366.txt -outfile=NM_001025366.entret
分子系統樹作成(clustalw使用)
分子系統樹を作成する時の手順についてまとめておく。
作業は以下の2段階に分けられる。
1:dnaやアミノ酸の配列を入力して、マルティプルアラインメントを行う。(生成するのは、"-.aln"ファイル)
$ % clustalw -input="inputfile.txt" -align -type=protein -matrix=blosum
2:マルティプルアラインメントの結果を基にして、系統樹のデータを出力する("-phb"ファイル等)
前々回のブログのp53のホモログをswissprotから取ってきたネタで言えば、
1 : EMOBSSのseqretで"p53_*"のキーワードで、p53プロテインのホモログを釣ってくる。
$ seqret swissprot:p53_* -out=p53_swissprot.txt
2:EMBOSSのseqretで"p53_*"で釣ってきたp53のホモログに対してマルティプルアラインメントを行う。
$ clustalw -infile=p53_swissprot.txt -align -type=protein -matrix=blosum
3 : マルティプルアラインメントのファイルを基にして系統樹を書かせる。
$ clustalw -infile=p53_swissprot.aln -tree -outputtree=p53_swissprot.phb
4 : njplotを用いて系統樹を描写する。(NJplotをインストールして使う)
$ sudo apt-get install njplot
$ njplot p53_swissprot.phb
#NJplotのウィンドウが開くので、GUI操作で、FILE -> Save as Postscrip
#生成したp53_swissprot.psファイルをpdfファイル、そしてpngファイルに変化する。
5 :生成したp53_swissprot.psファイルをpdfファイル、そしてpngファイルに変化する。
$ ps2pdf p53_swissprot.ps
$ convert p53_swissprot.pdf p53_swissprot.png
($ sudo apt-get install imagemagick b #imagemagicのインストール)
($ sudo apt-get install ps2pdf #ps2pdfのインストール )

作業は以下の2段階に分けられる。
1:dnaやアミノ酸の配列を入力して、マルティプルアラインメントを行う。(生成するのは、"-.aln"ファイル)
$ % clustalw -input="inputfile.txt" -align -type=protein -matrix=blosum
2:マルティプルアラインメントの結果を基にして、系統樹のデータを出力する("-phb"ファイル等)
前々回のブログのp53のホモログをswissprotから取ってきたネタで言えば、
1 : EMOBSSのseqretで"p53_*"のキーワードで、p53プロテインのホモログを釣ってくる。
$ seqret swissprot:p53_* -out=p53_swissprot.txt
2:EMBOSSのseqretで"p53_*"で釣ってきたp53のホモログに対してマルティプルアラインメントを行う。
$ clustalw -infile=p53_swissprot.txt -align -type=protein -matrix=blosum
3 : マルティプルアラインメントのファイルを基にして系統樹を書かせる。
$ clustalw -infile=p53_swissprot.aln -tree -outputtree=p53_swissprot.phb
4 : njplotを用いて系統樹を描写する。(NJplotをインストールして使う)
$ sudo apt-get install njplot
$ njplot p53_swissprot.phb
#NJplotのウィンドウが開くので、GUI操作で、FILE -> Save as Postscrip
#生成したp53_swissprot.psファイルをpdfファイル、そしてpngファイルに変化する。
5 :生成したp53_swissprot.psファイルをpdfファイル、そしてpngファイルに変化する。
$ ps2pdf p53_swissprot.ps
$ convert p53_swissprot.pdf p53_swissprot.png
($ sudo apt-get install imagemagick b #imagemagicのインストール)
($ sudo apt-get install ps2pdf #ps2pdfのインストール )

clustalについて
前回のブログで
コマンドライン上で
$ clustalw
を使った。
そもそもclustalとは
以下のようなアプリケーションを言うらしい。(Wikipedia: http://ja.wikipedia.org/wiki/Clustalより引用)
Clustalは広く用いられている多重整列プログラムである。現在はコマンドライン版のClustal WとGUI版のClustal Xとがある。欧州バイオインフォマティクス研究所のFTPサーバから入手できる。
以下の3つの段階を踏む。
これらは自動的に行われるが、ガイドツリーのみを計算させたり、ガイドツリーを指定して多重整列のみを行わせることもできる。
コマンドライン上で
$ clustalw
を使った。
そもそもclustalとは
以下のようなアプリケーションを言うらしい。(Wikipedia: http://ja.wikipedia.org/wiki/Clustalより引用)
Clustalは広く用いられている多重整列プログラムである。現在はコマンドライン版のClustal WとGUI版のClustal Xとがある。欧州バイオインフォマティクス研究所のFTPサーバから入手できる。
以下の3つの段階を踏む。
これらは自動的に行われるが、ガイドツリーのみを計算させたり、ガイドツリーを指定して多重整列のみを行わせることもできる。
emboss,(seqret) , clustalwを駆使してマルティプルアラインメントをしてみたよ(^^)
lubuntu 11.04 にて
#embossのインストール
$ sudo apt-get install emboss
#データベースの設定
$ sudo cp /usr/share/EMBOSS/emboss.default.template /usr/share/EMBOSS/emboss.default
#データベースの確認
$ showdb
# 設定ファイル(/usr/share/EMBOSS/emboss.default)の中で文頭に"#"がついているデータベースを"#"を削除することで有効化する。
$ sudo vim /usr/share/EMBOSS/emboss.default
#データベースの確認
$ showdb
# embossのseqretを使って、swissprotから、登録されている様々な種のp53タンパクの配列をとってくる。
$ seqret
Reads and writes (returns) sequences
Input (gapped) sequence(s): swissprot:p53_*
output sequence(s) [p53_barbu.fasta]: p53_swissprot.txt
#p53_swissprot.txtの中身を見る
$ less p53_swissprot.txt
#clustalwのインストール
$ sudo apt-get install clustalw
# clustalwによるマルティプルアラインメント
$ clustalw p53_swissprot.txt
#カレントディレクトリに出力ファイルができている。
$ ls
p53_swissprot.aln p53_swissprot.dnd p53_swissprot.txt
#結果を見てみる。
$ less p53_swissprot.aln
#マルティプルアラインメントの結果を美しく表示する(EMBOSSのprettyplot)
$ prettyplot p53_swissprot.aln
Draw a sequence alignment with pretty formatting
Graph type [x11]: ps #ここでpsを入力してpostscriptを作成させる
Created prettyplot.ps
#ポストスクリプトファイルをpdfファイルに変換
$ ls
p53_swissprot.aln p53_swissprot.dnd p53_swissprot.txt prettyplot.ps
$ sudo apt-get install ps2dpf
$ ps2dpf p53_swissprot.ps
$ ls
p53_swissprot.aln p53_swissprot.dnd p53_swissprot.txt prettyplot.pdf prettyplot.ps #pdfファイルができてる!!!!
#コマンドからpdfファイルを閲覧
$ xdpf prettyplot.pdf
#ブログにはpng, jpg, gifでしか貼れないのでpdfファイルをpngファイルに変換する。
$ sudo apt-get install imagemagick b #imagemagicのインストール
$ convert prettyplot.pdf prettyplot.png
$ ls
p53_swissprot.aln prettyplot-1.png prettyplot-5.png prettyplot.pdf
p53_swissprot.dnd prettyplot-2.png prettyplot-6.png prettyplot.ps
p53_swissprot.txt prettyplot-3.png prettyplot-7.png
prettyplot-0.png prettyplot-4.png prettyplot-8.png
#もとのpdfファイルが複数のページを持っていたので、ファイルもpngファイルも複数せ生成された。

#embossのインストール
$ sudo apt-get install emboss
#データベースの設定
$ sudo cp /usr/share/EMBOSS/emboss.default.template /usr/share/EMBOSS/emboss.default
#データベースの確認
$ showdb
# 設定ファイル(/usr/share/EMBOSS/emboss.default)の中で文頭に"#"がついているデータベースを"#"を削除することで有効化する。
$ sudo vim /usr/share/EMBOSS/emboss.default
#データベースの確認
$ showdb
# embossのseqretを使って、swissprotから、登録されている様々な種のp53タンパクの配列をとってくる。
$ seqret
Reads and writes (returns) sequences
Input (gapped) sequence(s): swissprot:p53_*
output sequence(s) [p53_barbu.fasta]: p53_swissprot.txt
#p53_swissprot.txtの中身を見る
$ less p53_swissprot.txt
#clustalwのインストール
$ sudo apt-get install clustalw
# clustalwによるマルティプルアラインメント
$ clustalw p53_swissprot.txt
#カレントディレクトリに出力ファイルができている。
$ ls
p53_swissprot.aln p53_swissprot.dnd p53_swissprot.txt
#結果を見てみる。
$ less p53_swissprot.aln
#マルティプルアラインメントの結果を美しく表示する(EMBOSSのprettyplot)
$ prettyplot p53_swissprot.aln
Draw a sequence alignment with pretty formatting
Graph type [x11]: ps #ここでpsを入力してpostscriptを作成させる
Created prettyplot.ps
#ポストスクリプトファイルをpdfファイルに変換
$ ls
p53_swissprot.aln p53_swissprot.dnd p53_swissprot.txt prettyplot.ps
$ sudo apt-get install ps2dpf
$ ps2dpf p53_swissprot.ps
$ ls
p53_swissprot.aln p53_swissprot.dnd p53_swissprot.txt prettyplot.pdf prettyplot.ps #pdfファイルができてる!!!!
#コマンドからpdfファイルを閲覧
$ xdpf prettyplot.pdf
#ブログにはpng, jpg, gifでしか貼れないのでpdfファイルをpngファイルに変換する。
$ sudo apt-get install imagemagick b #imagemagicのインストール
$ convert prettyplot.pdf prettyplot.png
$ ls
p53_swissprot.aln prettyplot-1.png prettyplot-5.png prettyplot.pdf
p53_swissprot.dnd prettyplot-2.png prettyplot-6.png prettyplot.ps
p53_swissprot.txt prettyplot-3.png prettyplot-7.png
prettyplot-0.png prettyplot-4.png prettyplot-8.png
#もとのpdfファイルが複数のページを持っていたので、ファイルもpngファイルも複数せ生成された。

lubuntuは軽いですね。
lubuntu 11.04 入れてみました
URL : http://lubuntu.net/
私の中古のlet's note cf-y5に。
内臓無線lanもいきなり認識してくれるし、
動作は軽いし、
日本語環境も問題なしだし、
幸せです(^^)
URL : http://lubuntu.net/
私の中古のlet's note cf-y5に。
内臓無線lanもいきなり認識してくれるし、
動作は軽いし、
日本語環境も問題なしだし、
幸せです(^^)
planexのgw-usnano2を使う。
 planexのgw-usnano2は極小の無線lan子機として大変人気のあるシリーズです。
planexのgw-usnano2は極小の無線lan子機として大変人気のあるシリーズです。そこで、私のubuntuでも使ってみようと思いました。
まずは、
http://218.210.127.131/downloads/downloadsView.aspx?Langid=4&PNid=48&PFid=48&Level=5&Conn=4&DownTypeID=3&GetDown=false&Downloads=true#RTL8192CU
にいって、CN1ってところをクリックします。
すると
というファイルがダウンロードできます。
これを
# zip形式の圧縮を解凍
$ unzip unzip RTL8192CU_linux_v3.0.1590.20110511.zip
# 解凍して生成したディレクトリに移動
$ cd RTL8192CU_8188CUS_8188CE-VAU_linux_v3.0.1590.20110511/
# インストールの開始
$ sudo sh install.sh
でいけました。
あとは特にいじらなくてもubuntuが認識してくれましたし、子機も赤い光を放ちながら動いてくれました。
診療ガイドラインのデータベース
患者さんの病気の診断をつけるのに各疾患の診療ガイドラインが必要になってきます。
これが疾患ごとに出版されているので、フォローするのが大変です。
いちいちガイドラインのハンドブックを購入しているとお金が持ちません。。
そこで、以下に紹介するデータベースがおすすめです。
東邦大学医学メディアセンター (Toho University Media Center)
http://www.mnc.toho-u.ac.jp/mmc/guideline/index.htm#bunken

これが疾患ごとに出版されているので、フォローするのが大変です。
いちいちガイドラインのハンドブックを購入しているとお金が持ちません。。
そこで、以下に紹介するデータベースがおすすめです。
東邦大学医学メディアセンター (Toho University Media Center)
http://www.mnc.toho-u.ac.jp/mmc/guideline/index.htm#bunken

ubuntuをインストールしてからまずやること集まり!!!!!!!!
1 ホームディレクトリのディレクトリ名を英語に変える
$ LANG=C xdg-user-dirs-gtk-update
で開いてきたウィンドウ内で[Update Names」
そして
$ sudo shutdown -r now
で再起動
こんどは英語から日本語にするか聞いてくるが、これは二度と聞かせようにチエックいれてお断り。
2 システムのアップデート
アップデートマネージャーからシステムのアップデート
3 軽量デスクトップ環境のインストール(lubuntu etc)
synapticマネージャーからlubuntuと検索して、lubuntu desktop環境に依存関係のあるソフトウェアーを一括ダウンロード&インストール
インストールの途中で、デフォルトのディスプレイマネージャーを聞いてくるが、今後、GNOMEとkubuntuの両方を使うことを視野に、gdmのままでいく。
インストール終了後は一度再起動し、システム-ログイン画面-デフォルトをLubuntuにします。
4 ubuntuのパッケージ管理システムをアップデート
$ sudo apt-get update
5 辞書系ソフトのgwaeiとgjitenのインストール
$ sudo apt-get install gwaei
$ sudo apt-get install gjiten
6 vimエディタをインスール&設定
$ sudo apt-get install vim
$ vim ~/.vimrc
7 freemindのインストール
$ sudo apt-get install freemind
8 GUI操作で、クロームブラウザとDropboxを取ってきてインストール
9 デスクトップの壁紙を好きなものに変える
lubuntuなら、テーマが青なので”ubuntu blue”などとググって、素敵なwallpaperを探す。

$ LANG=C xdg-user-dirs-gtk-update
で開いてきたウィンドウ内で[Update Names」
そして
$ sudo shutdown -r now
で再起動
こんどは英語から日本語にするか聞いてくるが、これは二度と聞かせようにチエックいれてお断り。
2 システムのアップデート
アップデートマネージャーからシステムのアップデート
3 軽量デスクトップ環境のインストール(lubuntu etc)
synapticマネージャーからlubuntuと検索して、lubuntu desktop環境に依存関係のあるソフトウェアーを一括ダウンロード&インストール
インストールの途中で、デフォルトのディスプレイマネージャーを聞いてくるが、今後、GNOMEとkubuntuの両方を使うことを視野に、gdmのままでいく。
インストール終了後は一度再起動し、システム-ログイン画面-デフォルトをLubuntuにします。
4 ubuntuのパッケージ管理システムをアップデート
$ sudo apt-get update
5 辞書系ソフトのgwaeiとgjitenのインストール
$ sudo apt-get install gwaei
$ sudo apt-get install gjiten
6 vimエディタをインスール&設定
$ sudo apt-get install vim
$ vim ~/.vimrc
syntax on
set number
set number
set cindent
7 freemindのインストール
$ sudo apt-get install freemind
8 GUI操作で、クロームブラウザとDropboxを取ってきてインストール
9 デスクトップの壁紙を好きなものに変える
lubuntuなら、テーマが青なので”ubuntu blue”などとググって、素敵なwallpaperを探す。

treeコマンドによりディレクトリのツリーを一発で表示!!!!
ディレクトリのツリーを一発で表示するtreeコマンドなるものを発見。
デフォルトではubuntuに入っていないため、
$ sudo apt-get install tree
でOK
日本語の文字化けを防ぐために、引数を追加して以下のようにしてやれば、カレントディレクトリを起点としたツリーを作成することができます(^ ^)
$ tree -N PATH . > tree.txt
tree.txtというファイルにディレクトリの内容が出力されています♪

デフォルトではubuntuに入っていないため、
$ sudo apt-get install tree
でOK
日本語の文字化けを防ぐために、引数を追加して以下のようにしてやれば、カレントディレクトリを起点としたツリーを作成することができます(^ ^)
$ tree -N PATH . > tree.txt
tree.txtというファイルにディレクトリの内容が出力されています♪

X Window使用時の仮想コンソール
X Window 画面になっているときに、仮想コンソール1~6にきりかえるときは、
Ctrl + Alt + F1~F6
となる。
X Window 画面に戻るときは
Alt + F7
で戻れる。
Ctrl + Alt + F1~F6
となる。
X Window 画面に戻るときは
Alt + F7
で戻れる。
ubuntuをlubuntuデスクトップに変更する。
ubuntu11.04をインストールしてしばらくはclassicデスクトップをデフォルトに変更して使っていたんですが、それでもやはり動作が遅いのが気になりました。
そこで、”Lubuntu”のデスクトップをインストールしてデフォルトに変更してやりました(^-^)
方法は簡単。
1 synapticマネージャーにいく
2 lubuntuと検索して、lubuntuデスクトップで右クリック。そして依存関係にあるものをすべてインストール。
3 ログイン画面の設定から[lubuntuをデフォルトセッションにする」でOK!!!

そこで、”Lubuntu”のデスクトップをインストールしてデフォルトに変更してやりました(^-^)
方法は簡単。
1 synapticマネージャーにいく
2 lubuntuと検索して、lubuntuデスクトップで右クリック。そして依存関係にあるものをすべてインストール。
3 ログイン画面の設定から[lubuntuをデフォルトセッションにする」でOK!!!

ubuntu用オフライン辞典 Gjiten
ubuntuをネットにつながっていない状況でどうしても使用したいときに、便利なオフライン辞典。
今日は、Gjitenというアプリがapt-getコマンドで入手でき、かつ強力なツールであることが判明しましたのでお伝えします。
まずはインストールの手順
$ sudo apt-get install gjiten
これでOK
コマンドラインから
$ gjiten
と入力すれば開けます。

今日は、Gjitenというアプリがapt-getコマンドで入手でき、かつ強力なツールであることが判明しましたのでお伝えします。
まずはインストールの手順
$ sudo apt-get install gjiten
これでOK
コマンドラインから
$ gjiten
と入力すれば開けます。

nautilusによってカレントディレクトリをGUIで表示
nautilusはGNOMEデスクトップの標準ファイルマネージャーです。
端末を使っている時も、nautilusを呼び出すことができます。
例えば、カレントディレクトリを呼び出そうと思ったら、
$ nautilus . &
&(アンパーサ)を末尾につけてバックグラウンドジョブにしないと、フォワグラウンドジョブになっちゃうんで不便ですね。
ubuntu 11.04 重い
unityっていうデスクトップに変更されたことによりクソ重くなってました。
もはや、わたしのCore Duoでも全然うごきませんでした。
設定を変更してubuntu classicていうのしてやれば昔のように軽快に動きます。
それにしても、ubuntuはどこへむかっているのでしょうか。
もはや、わたしのCore Duoでも全然うごきませんでした。
設定を変更してubuntu classicていうのしてやれば昔のように軽快に動きます。
それにしても、ubuntuはどこへむかっているのでしょうか。
REBASEからbionetファイルのダウンロード
分子生物学実験をしていますと制限酵素処理をすることが多いので、ここで便利な情報を。
全制限酵素の認識配列をまとめたファイル(bionet file)の最新版を取ってきます。
REBASEのHPに行って
http://rebase.neb.com/rebase/rebase.html
REBASE FILESをクリック。
IGSuite (bionet)をクリック。
bionet.###をクリック。
右クリックで名前を付けて保存。
全制限酵素の認識配列をまとめたファイル(bionet file)の最新版を取ってきます。
REBASEのHPに行って
http://rebase.neb.com/rebase/rebase.html
REBASE FILESをクリック。
IGSuite (bionet)をクリック。
bionet.###をクリック。
右クリックで名前を付けて保存。
